In my last post I showed how to decode morse code in Python using list comprehensions. In this post I show how to do it in F# instead.
First using list comprehensions:
let codes =
[("A",".-"); ("B","-..."); ("C","-.-."); ("D","-.."); ("E",".");
("F","..-."); ("G","--."); ("H","...."); ("I",".."); ("J",".---");
("K","-.-"); ("L",".-.."); ("M","--"); ("N","-."); ("O","---");
("P",".--."); ("Q","--.-"); ("R",".-."); ("S","..."); ("T","-");
("U","..-"); ("V","...-"); ("W",".--"); ("X","-..-");("Y","-.--");
("Z","--..")]
let rec decode input =
if input = "" then [""]
else [ for c, code in codes when input.StartsWith(code)
for rest in decode(input.Substring(String.length code))
-> c + rest ]
As it can be seen the code is almost identical to the Python code. Incidentally, I could not find a function equivalent to Python’s startswith method in the O’Caml standard library (without using regular expressions). Fortunately F# came with one from the .NET library.
Much to my the surprise the compiled F# (running on Mono 1.2.4) is 4 times slower that the Python code. I then rewrote the program to use sequence comprehensions:
let rec decode input =
if input = "" then { -> "" }
else { for c, code in codes when input.StartsWith(code)
for rest in decode(input.Substring(String.length code))
-> c + rest }
This version runs faster, and uses only a constant amount of memory. Still the Python version is three and half times faster.
I then tried to run the programs on an other computer with Microsoft’s .NET implementation. This improved the F# running times a lot. However, they are still 40% to 80% slower than the Python version.
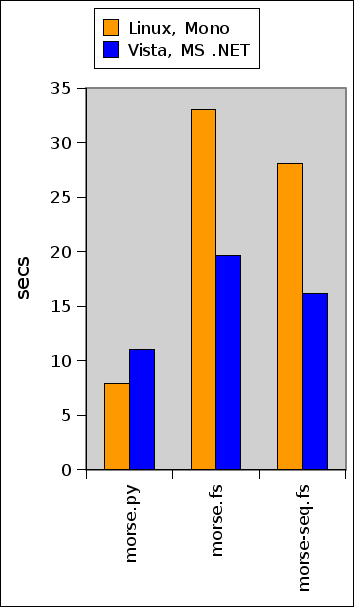
My current guess is that Python is much better at handling strings than .NET.
The actual numbers:
| Linux, Mono | Vista, MS .NET | |||
|---|---|---|---|---|
| Program | Time sec |
Ratio | Time sec |
Ratio |
morse.py |
7.94 ± 0.05 | 1 | 11.03 ± 0.03 | 1 |
morse.fs |
33.07 ± 0.19 | 4.17 | 19.65 ± 0.33 | 1.78 |
morse-seq.fs |
28.1 ± 0.59 | 3.54 | 16.12 ± 0.36 | 1.46 |
Update 2007-11-12 Added test files:
- Python code:
morse.py - F# code using list comprehensions:
morse.fs - F# code using sequence comprehensions:
morse-seq.fs
My understanding is that at least in the non-Windows case F# is still using the pre-generics runtime because we do not support precompilation of assemblies when they contain generic code.
I believe that if you force F# to use the 2.0 profile version you will get better performance under Mono.
Hi Miguel
A quick test with the flags
--generics --cli-version 2.0tofcsgives no difference in performance.I am just about to complete a version in C# to see if it F# or CLR that is the problem.
Hi Ken,
I’d be interested in having the test data you used, it would be difficult to tune the F# program with out this.
Thanks,
Rob
Hi Robert,
I have added links to the python version and the two F# versions I have used.
Note that, I do know that the algorithm that all versions of the program uses is not optimal. It would, for instance, be better to generate the solutions backwards. So that suffixes for strings that starts with
AorET, for instance, is only generated once.Let me know your findings.
Cheers,
–Ken
Hi Ken,
Nice code! I’m glad you spotted the sequence expression optimization: that’s very nice.
With regard to performance: we’ve tracked this as bug 1253 in our internal database. The issue has been resolved and the optimizations will be available in the next release. You should see substantial improvements across the board here.
After the optimziations are made the sample code as written becomes dominated by string allocations, and hence the performance is not really a language issue: it becomes more to do with string representations and allocation rates. For example your use of Unicode strings here will mean you pay extra, and perhaps byte strings should be used instead. But as you know the algorithm has room for improvement because of over-allocation.
With regard to sequence expressions, the ideal implementation is to generate C#-style iterator classes. That is something we expect to do at some point: it means certain very elegant sequence expressions will execute extremely efficiently. However, the current performance profile of sequence expressions is good for most applications.
Kind regards
Don